Die Dokumentenklassifizierung ist ein wichtiger Bestandteil digitaler Posteingangsprozesse (Digital Mailroom). Klassisches Machine Learning (ML) erzielt in produktiven Anwendungen stabile Resultate, stösst jedoch dort an Grenzen, wo nur wenige Dokumente für das Training der ML-Modelle vorhanden sind oder deren Inhalte stark variieren. Mit der zunehmenden Leistungsfähigkeit von Large Language Models (LLM) stellt sich die Frage, ob diese eine Alternative oder eine sinnvolle Ergänzung zu ML-Modellen für die Dokumentenklassifizierung darstellen können. Eine Studie im Rahmen einer MAS-Arbeit an der
ZHAW, Zürcher Hochschule für Angewandte Wissenschaften, School of Management and Law, hat das Potenzial von Retrieval-Augmented Generation (RAG) in diesem Bereich anhand eines Anwendungsfalls aus der Praxis untersucht. RAG ist eine Methode, bei der ein Retrieval-System themenbezogene Dokumente aus einer externen Wissensbasis (z.B. einer Vektorendatenbank) abruft und dem LLM als Kontext bereitstellt, damit dieses präzisere und besser begründete Antworten generieren kann.
Testaufbau und Modellvarianten
Zur Untersuchung wurde ein RAG‑Prototyp entwickelt, der den Volltext eingehender Dokumente verarbeitet und mithilfe einer Vektorendatenbank passenden Kontext abruft. Die Datenbank besteht aus Textauszügen vorklassifizierter Dokumente aus dem digitalen Posteingang. Bei der Klassifizierung werden sie als Kontext in den Prompt an das LLM eingebettet, welches die Klassifizierung vornimmt und eine nachvollziehbare Begründung der Resultate generiert. Getestet wurde mit drei verschiedenen LLMs mit unterschiedlichem Leistungsvermögen (Gemma 3‑27B, Phi 4‑14.7B und GPT‑4o). Die Ergebnisse wurden anschliessend mit einer produktiv eingesetzten Machine-Learning‑Komponente verglichen. Die Datengrundlage bestand aus 3360 realen Dokumenten aus 97 verschiedenen Dokumentklassen, von Kreditorenrechnungen über Anmeldeformulare bis hin zu Korrespondenz. Sie wurden aus dem digitalen Posteingang einer grossen Schweizer Unternehmung in der Immobilienbewirtschaftung entnommen, wodurch eine realitätsnahe Bewertung der Leistungsfähigkeit möglich wurde. Der Schwerpunkt der Analyse lag auf der Klassifizierungsqualität, auf wiederkehrenden Unterschieden im Klassifizierungsverhalten der Modelle sowie auf der Verarbeitungsgeschwindigkeit. Zum Testaufbau ist hinzuzufügen, dass 30 der 97 Klassen in der Vektorendatenbank des Prototyps nicht abgedeckt waren. Weiter wurde die Applikation nicht produktionsreif aufgebaut. Somit ist die Übertragbarkeit der Ergebnisse auf produktive Anwendungen gesondert zu prüfen.
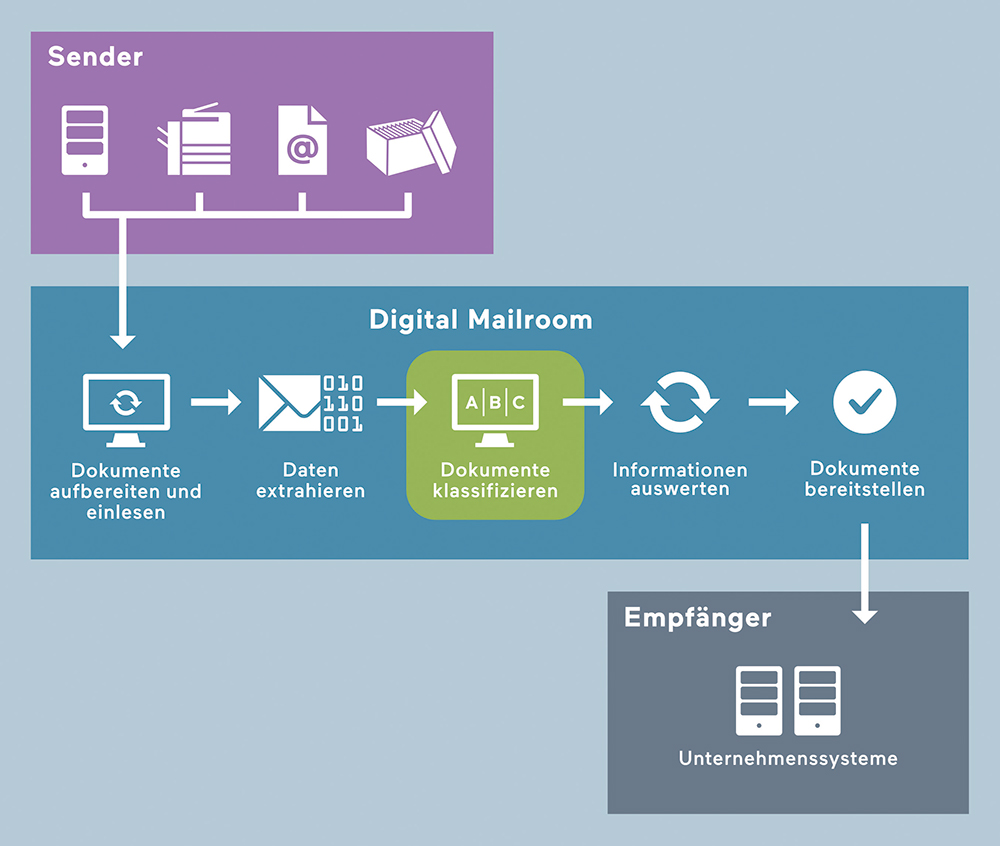
Schematische Funktionsweise eines Digital Mailroom. Der Fokus des Pilotprojektes lag auf der Dokumentenklassifizierung. (Quelle: Arcplace/ZHAW)
ML dominiert klar
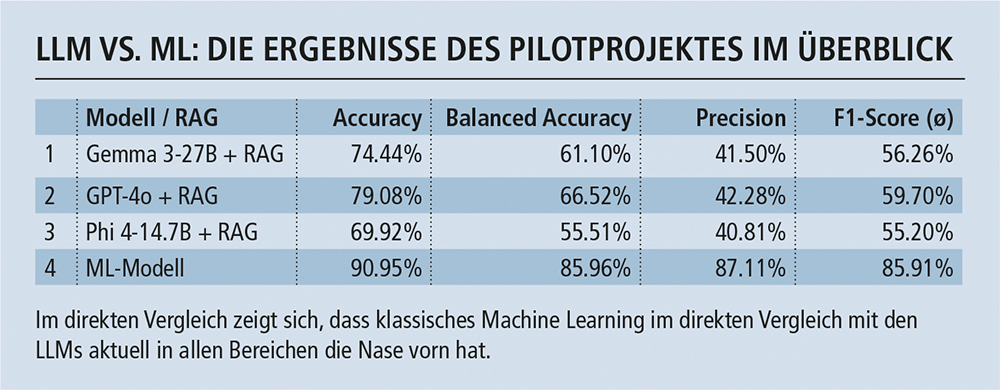
Die Ergebnisse der Evaluationsläufe zeigen zunächst ein konsistentes Muster: Die getesteten RAG‑Konfigurationen erreichen nicht das Niveau der ML‑Lösung. Das generative Modell (GPT‑4o), das im Test am besten abschnitt, erzielte rund 79 Prozent korrekt klassifizierte Dokumente (Accuracy). Die ML‑Komponente lag für dasselbe Set an Dokumenten bei 91 Prozent. Dieser Unterschied zeigte sich nicht nur bei der Gesamtgenauigkeit, sondern ebenso bei weiteren Gütemassen, wie Balanced Accuracy, Precision und F1‑Score. Eine Erweiterung der Wissensbasis an vorklassifizierten Dokumenten in der Vektorendatenbank führte zwar zu einer moderaten Verbesserung, reichte jedoch nicht aus, um die Genauigkeit des ML-Modells zu erreichen. Auf die Effizienz übertragen würde der RAG-Prototyp mit GPT-4o produktiv zu 8,39 Sekunden manuellem Aufwand führen gegenüber 7,50 Sekunden mit der bestehenden ML-Konfiguration (+11,87 %).
Stärken von RAG: Seltene und komplexe Dokumentenklassen
Besonders aufschlussreich waren die Klassifizierungsergebnisse für selten vorkommende Dokumenttypen. Hier hatte der RAG-Prototyp klare Vorteile. Bei Dokumentenarten, für die nur wenige Trainingsbeispiele zur Verfügung standen, gelang es RAG häufiger, die korrekte Kategorie zu identifizieren. Die Klasse der Kreditorengutschriften liefert dafür ein gutes Beispiel. Während das ML‑Modell häufig zur falschen Einordnung als Kreditorenrechnung tendierte, konnte der RAG-Prototyp mit GPT‑4o und Gemma 3‑27B diesen Dokumenttyp zuverlässiger vorhersagen. Die Stärke des RAG liegt im inhaltlichen Verständnis, das auch mit wenigen Beispielen eine korrekte Zuordnung ermöglicht. RAG profitiert davon, dass es beim Abweichen vom bekannten Terrain nicht allein statistische Muster repliziert, sondern semantische Zusammenhänge berücksichtigt.
Bedeutung der Wissensbasis für das Retrieval
Bei der Analyse der Fehlklassifizierungen zeigte sich ein durchgehender Trend: Immer dann, wenn die Vektorendatenbank keine geeigneten Beispiele enthielt, reduzierte sich die Leistung des Modells erheblich. Das Fehlen von Kontext führte zu unplausiblen oder unsicheren Antworten, selbst dann, wenn das zugrunde liegende LLM grundsätzlich leistungsfähig war. Dieses Ergebnis macht deutlich, dass die Qualität und Abdeckung der Wissensbasis mindestens so entscheidend sind wie die Modellwahl. In einer realen Anwendung würde die Vektorendatenbank zudem kontinuierlich gepflegt werden müssen, um veränderte Dokumentstile, neue Formate oder saisonale Ausprägungen abzubilden. Damit verschiebt sich die Herausforderung vom Modelltraining zum Wissensmanagement, was RAG sowohl flexibel als auch anspruchsvoll macht.
Ein positiver Nebeneffekt des RAG‑Ansatzes liegt in der generierten Begründung zu jeder Klassifizierung. Diese Erklärungen machen den Prozess besser nachvollziehbar und erleichtern menschliche Validationsschritte. Gegenüber einem ML-System bietet RAG den Vorteil, dass die getroffenen Entscheidungen mit einer verständlichen Begründung belegt werden können. Dies wirkt sich nicht unmittelbar auf die Messwerte der Klassifizierung aus, trägt jedoch zu mehr Erklärbarkeit bei und wirkt unterstützend für Menschen, die in den Prozess eingebunden sind.
Verarbeitungszeit: Infrastruktur ist entscheidend
Die Messungen der Verarbeitungszeit offenbarten erhebliche Unterschiede zwischen den Modellvarianten. GPT‑4o, betrieben auf der Microsoft-Azure-Plattform und integriert über OpenAI API, klassifizierte Dokumente im Durchschnitt in unter zwei Sekunden. Demgegenüber wurden die Modelle Gemma 3-27B und Phi 4 14.7B in einer lokalen Entwicklungs- und Testumgebung (GPU: Nvidia Geforce RTX 4090 24 GB VRAM; CPU: Intel Core i9-14900K 3,6 GHz, 64 GB RAM) betrieben und benötigten mehrere Sekunden pro Dokument. Für digitale Posteingänge mit hohem Volumen ist dieser Unterschied entscheidend, da die Klassifizierung eine seriell ausgeführte Aufgabe darstellt. In der Praxis stehen Unternehmen hier vor einem Spannungsfeld zwischen Geschwindigkeit, Kosten und Compliance, da proprietäre Modelle nicht in jedem regulatorischen Umfeld eingesetzt werden dürfen.
Vielversprechend, aber noch nicht reif für die Ablösung
Die Gesamtbetrachtung der Resultate zeigt, dass der entwickelte RAG‑Prototyp die eingesetzten ML‑basierten Klassifikatoren in Bezug auf breite Einsatzfähigkeit und konsistent hohe Genauigkeit nicht erreicht. Gleichzeitig weist der Ansatz genau dort Stärken auf, wo ML traditionell Schwächen hat. Beispiele dafür sind seltene Klassen oder inhaltlich komplexe Dokumente, die ein umfassendes Textverständnis erfordern. Auch die Fähigkeit eines LLM, Klassifizierungen zu begründen, eröffnet neue Möglichkeiten für das Verständnis der Ergebnisse. Dadurch können sowohl die manuelle Validierung als auch die Analyse von Fehlklassifizierungen erleichtert werden.
Die Resultate weisen darauf hin, dass RAG aktuell weniger als Konkurrenz, sondern vielmehr als komplementäre Technologie betrachtet werden sollte. Während klassische ML‑Modelle weiterhin die höchste Gesamtzuverlässigkeit bieten, kann RAG deren Schwächen punktuell kompensieren und gleichzeitig Transparenz sowie Flexibilität erhöhen. Die Technologie befindet sich an einem vielversprechenden Punkt: Sie ist leistungsfähig genug, um echten Mehrwert zu bieten, aber noch nicht ausgereift genug, um etablierte Lösungen im Bereich der Dokumentenklassifizierung im digitalen Posteingang vollständig abzulösen. Es ist anzunehmen, dass die nähere Zukunft in hybriden Klassifizierungsarchitekturen liegt, in denen generative Modelle mit oder ohne RAG zusammen mit ML eingesetzt werden.
Die Autoren
Johannes Egli (links) ist Principal Consultant mit 15 Jahren Erfahrung in der Analyse, Gestaltung und Automatisierung dokumentenbasierter Geschäftsprozesse. Er arbeitet bei
Arcplace als Berater und Lösungsarchitekt an der Schnittstelle von Fachbereich und IT. Arcplace ist ein Schweizer IT‑Dienstleister, der Organisationen bei der Digitalisierung, Automatisierung und sicheren Archivierung dokumentenbasierter Geschäftsprozesse unterstützt.
Mario Gellrich (rechts) ist Dozent für Wirtschaftsinformatik und Data Science an der
ZHAW. Seine Arbeits- und Forschungsschwerpunkte liegen unter anderem in den Bereichen Machine Learning, Natural Language Processing und Generative Künstliche Intelligenz.