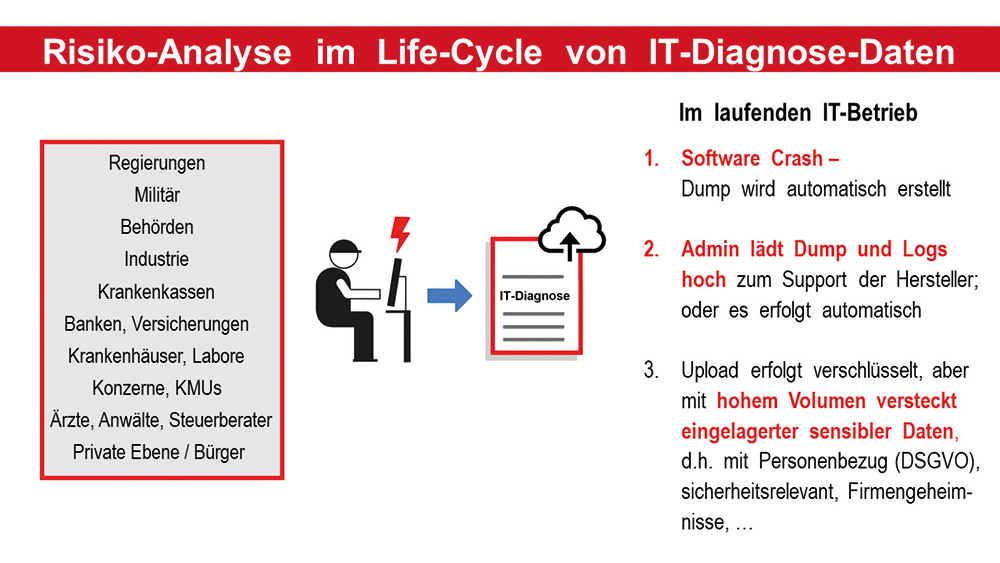
Auf die Agenda der IT-Auditoren und IT-Revisoren ist ein neues Thema gelangt: die Prüfung von IT- und KI-Diagnose-Daten. Bei nicht gesetzeskonformem Umgang mit diesen beiden Dokumenten-Gattungen entstehen zwei gravierende Risiken.
Zum einen sind IT-Diagnose-Daten ein Sicherheitsrisiko. Seitdem 2023 chinesische Hacker des Storm-0558 im Microsoft-Unternehmen einen Microsoft Master Key entwendet und damit u.a. Outlook-Konten der US-Behörden ausspioniert haben, kann die «Gefahrenquelle Dump» weltweit nicht mehr ignoriert werden. Denn man vermutete, dass der Key aus einem Crash Dump extrahiert wurde.
So sind insbesondere Crash Dumps wahre Fundgruben für Hacker. Bei einem Computer-Crash oder Applikationsabsturz werden für die Problemanalyse alle Speicherinhalte und damit Informationen über die betroffenen IT-Systeme in einen Crash Dump geschrieben. Hierin enthalten sind auch sicherheitskritische Details, wie zum Beispiel Keys, Passwörter oder Zertifikate. Werden diese sensiblen Daten nicht anonymisiert, sind sie eine wertvolle Beute für alle, die Zugang zu diesen IT-Diagnose-Daten haben. Sie können für einen gezielten Angriff genutzt werden. Weitere typische IT-Diagnose-Daten sind System- und Applikations-Logs und Netzwerk-Traces.
Das zweite Risiko betrifft den Schutz der in IT-Diagnose-Dateien enthaltenen Daten mit Personenbezug und damit die Einhaltung der revDSG- bzw. DSGVO-Compliance. Denn insbesondere Dumps und Logs aus produktiven IT- und KI-Umgebungen enthalten neben obigen Sicherheitsdaten meistens auch grosse Mengen hochsensibler personenbezogener Daten. Dies sind zum Beispiel Kunden-, Finanz- und Sozialdaten sowie unternehmensindividuelle Geschäftsgeheimnisse oder Daten aus Prompts für KI-Anwendungen. Alle diese Daten sind für die Problemanalyse nicht notwendig und damit vollkommen zweckfremd. Gemäss der Datenschutzanforderungen der revDSG und der DSGVO sollten sie auf keinen Fall Dritten zur Kenntnis gelangen. Sonst begeht der IT-Verantwortliche, der über die Weitergabe von IT-Diagnose-Daten an Hersteller entscheidet, potentiell einen Rechtsverstoss.
Warum sollten KI-Diagnose- von IT-Diagnose-Daten abgegrenzt werden? Es ist ihr spezifischer Charakter, der insbesondere die Datenschutz-Problematik in den Vordergrund stellt. KI-Diagnose-Daten entstehen primär durch eine fortlaufende Protokollierung sämtlicher KI-operativer Verarbeitungen. Diese umfassen das Trainieren der Modelle, die fortlaufenden Predictions mittels neuer Daten oder die aus den Vorverarbeitungen empfangenen User-Prompts und Bot-Dialoge. Diese sind u.U. verbunden mit Angaben zu den Nutzern, wie Namen, Profile, IP-Adressen, etc. Intensives Protokollieren ist aufgrund des hohen Lern-, Erfahrungs- und Erkenntnisbedarfs bei Entwicklung und Betrieb einer KI ein notwendiger Standard. Dies betrifft das gesamte modell-operative Umfeld und auch die Vorverarbeitung des Inputs für die Entwickler und Betreiber. Ohne intensives Logging geht es nicht, denn oftmals werden in einer anschliessenden «Raffination» aus den Log-Daten neue Trainingsdaten gewonnen. Ohne diesen Input kann man die Ursache für eine bestimmte Prediction als Modell-Ergebnis kaum erschliessen. Denn eine Analyse rein auf der Basis der vorliegenden Modell-Datei, d.h. des riesigen Konglomerats an Zahlen, ist kaum möglich. Im Fall des Fremdbezugs von KI-Modellen benötigt der Modell-Anbieter zur Bearbeitung gemeldeter Qualitätsmängel unbedingt die Original-Input-Daten. Er muss z.B. deren spezielle Struktur analysieren oder das Modell damit gezielt trainieren bzw. «fine-tunen». Dies ist eine Situation, die Parallelen zum Crash-Dump aufweist. Tiefgreifende Software-Fehler können ohne detaillierte Diagnose-Daten nicht identifiziert und korrigiert werden. KI-Diagnose-Daten sind jedoch im Vergleich zu IT-Diagnose-Daten vorwiegend Klartext- und keine binär codierten Daten. Es sind z.B. Logs, die fortlaufend aus entsprechenden Python-Programmen «fliessen».
Die Risiken um IT- und KI-Diagnose-Daten realisieren sich in ihrer gefährlichen Tragweite, wenn diese Daten das Haus verlassen, wie typischerweise im Moment des Uploads zu den Herstellern oder deren Partner bzw. Subunternehmen. Und wie oft tritt dieses Risiko ein? Nahezu täglich! Denn Uploads von Diagnose-Daten gehören zur Routine eines jeden professionellen IT-Betriebs. So werden z.B. Dumps und Logs als Anhänge von Tickets, zur Anforderung einer Fehleranalyse oder der Pflege und Weiterentwicklung, regelmässig verschickt. In manchen IT-Betrieben erfolgt der Upload sogar automatisch und damit unbemerkt – eine Art «Worst Case».
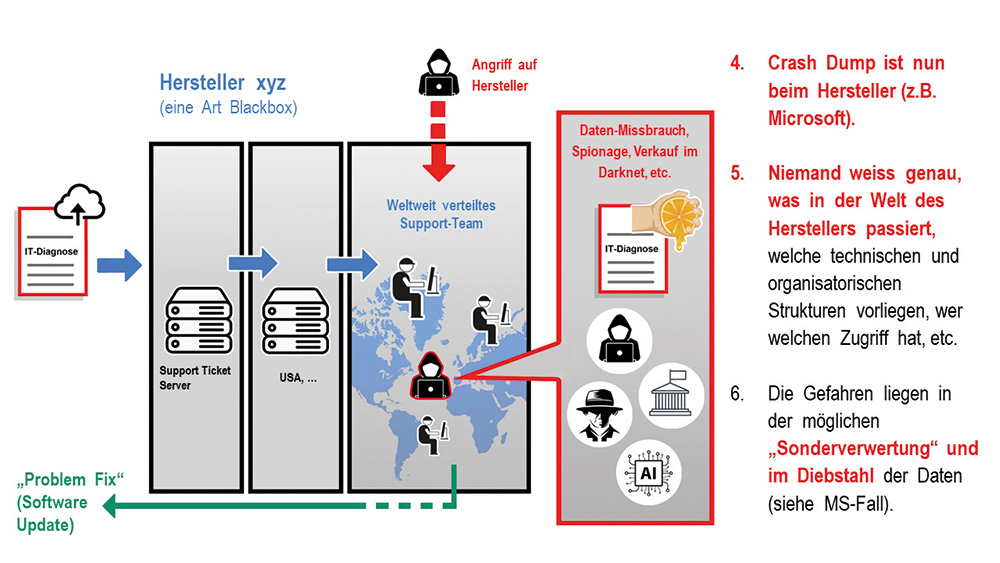
Regelmässigen Zugang zu den «inhaltsreichen» IT-Diagnose-Daten erhalten die weltweiten Software-Anbieter und IT-Dienstleister somit durch den Upload der Dumps und Logs ihrer Support-Kunden. Die Entwicklungs- und Supportzentren der Provider befinden sich meist ausserhalb der Schweiz und Europas, also in USA, Indien, Osteuropa oder China. Im Sinne des Datenschutzes besitzen sie oft kein gleichwertiges Schutzniveau wie die Schweiz. Jedoch auch in Ländern mit gleichwertigem Schutzniveau, wie der EU, bieten die unverhältnismässig umfangreich und zweckfremd in Dumps und Logs versteckt enthaltenen Daten eine grosse Vielfalt datenschutzrechtlicher und sicherheitskritischer Angriffsflächen.
Vergleichbar mit den IT-Diagnose-Daten erhalten KI-Modell-Anbieter und KI-Service-Provider Zugang zu den KI-Diagnose-Daten. Dies erfolgt im Rahmen der Nutzeranforderung zu Korrektur, Pflege und Weiterentwicklung von Modellen. Die Unterscheidung und Abgrenzung der KI-Diagnose-Daten von sensiblen Life-Daten im KI-Umfeld wird natürlich dann hinfällig, wenn die Anwender ihre nativen Input-Daten zur Nutzung einer SaaS-basierten KI zum Anbieter übertragen. Das besondere Augenmerk auf KI-Diagnose-Daten, verbunden mit einer speziellen Handhabung, ist bei ausserplanmässigen Support-bedingten Übertragungen von Originaldaten notwendig. Das zu IT-Diagnose-Daten analoge Risiko entsteht dann, wenn Original-Input-Daten zu Support-Zwecken, ohne grössere Aufmerksamkeit und damit Compliance-Prüfung, das Haus «lautlos» verlassen. D.h. in diesen für die Praxis nicht unüblichen Situationen des IT- und KI-Betriebs fehlen meist spezielle rechtliche Vereinbarungen für den Datentransfer. Auch werden die Daten vor der Übertragung in der Regel nicht geprüft, anonymisiert oder gefiltert.
Sämtliche Sicherheits- und Datenschutz-Risiken, die durch die Übertragung von IT- und KI-Diagnose-Daten an Dritte entstehen, können – «schmerzhafte» – regulatorische Verletzungen zur Folge haben. In der Schweiz sind dies z.B. Verstösse gegen das Informationssicherheitsgesetz (ISG), die Nationale Strategie zum Schutz der Schweiz vor Cyber-Risiken (NCS), die Regierungs- und Verwaltungsorganisationsgesetz (RVOG), die FINMA-RS 23/1 «Operationelle Risiken und Resilienz – Banken», die FINMA-RS 13/3 «Prüfwesen» sowie das revDSG und die DSGVO. Sämtliche Regelungen beinhalten potentielle Gefahren wie Beweislastumkehr, Busse, Schadensersatz, Rechtskosten, Reputationsschaden etc.
Man könnte annehmen, dass die Verschlüsselung der Daten eine compliancegerechte Lösung bieten würde. Leider nein, denn die IT-Diagnose-Daten werden zur Fehleranalyse entschlüsselt und verarbeitet. Den Herstellern liegen faktisch unverschlüsselte Originaldaten vor. Daraus ergeben sich grundsätzliche Gefahren einer zweckfremden «Sonderverwertung»:
a) die gezielte Extraktion von Daten durch den Hersteller für eigene Zwecke,
b) der gezielte Zugriff auf IT-Diagnose-Dokumente ausgewählter IT-Betriebe durch Geheimdienste oder Behörden auf Basis spezieller Gesetze – Stichwort digitale Souveränität,
c) die verbotene «Sonderverwertung» der Dokumente durch Mitarbeiter des Herstellers, oder dessen Subunternehmer, z. Bsp. in Form der Datenextraktion, des Verkaufs im Darknet, der Erpressung, etc.,
d) die Entwendung der IT-Diagnose-Daten durch Hacker von den Systemen des Herstellers, wie im vermeintlichen «Microsoft Dump Hack». Die Ergiebigkeit von Dumps produktiver Systeme macht sie schlichtweg zur Blaupause für einen «perfekten Hack». Dumps aus interessanten IT-Umgebungen haben daher einen realen Marktwert, z.B. in entsprechenden Fachkreisen des Darknets.
Die Vielfalt der Risikofaktoren und das Unvermögen einer wirklichen Kontrolle, insbesondere aufgrund der Menge an Mitwirkenden und deren weltweiten Lokationen, wecken das begründete Interesse von Risiko-Management und Revision.
Entsprechend hat sich ein neues Prüffeld für IT-Audit und IT-Revision entwickelt. Es lässt sich am besten mittels des Prüfkatalogs «IT- Diagnose-Daten» monitoren. Er umfasst rund 45 Prüfthemen, aufgeteilt nach «Grundsätzlichen Prüfthemen», «Inhouse IT-Diagnose-Daten», «IT-Diagnose-Daten bei Cloud & Co.» und «Stichprobenprüfung IT-Diagnose-Daten». Seine Veröffentlichung durch das ISACA Germany Chapter in der Zeitschrift IT-Governance Heft 40 Dezember 2024 fand sehr grosses Interesse, und er wird von Revisoren bereits für gezielte Prüfungen praktisch angewandt.
Beispielhafte Auszüge aus dem Prüfkatalog: siehe Bilder. Der gesamte umfassende Prüfkatalog (G.01-27, I.01-05, K.01-05, E.01-03, S.01-10) ist
hier downloadbar.
(Quelle: Stephen Fedtke in: IT-Governance Heft 40, Dezember 2024)
(Quelle: Stephen Fedtke in: I T-Governance Heft 40, Dezember 2024)
Wie das Problem lösen? IT- und KI-Diagnose-Daten sind in der gleichen Risiko- und Sicherheitsstufe wie Produktivdaten einzuordnen und zu schützen. Einen solchen revisionsgerechten Schutz bieten Werkzeuge zur lokalen Anonymisierung der IT-Diagnose-Daten vor dem Upload zum Software-Hersteller. Ihre Verfügbarkeit, wie z.B. durch die Lösung SF-SafeDump, hat den Einsatz von Anonymisierung mittlerweile zum Stand der Technik werden lassen. Viele Normen, Verordnungen und Gesetze verpflichten zu Lösungen nach «Stand der Technik». Somit erfüllt die Risikovorsorge mittels Anonymisierung im Bereich KI- und IT-Diagnose-Daten eine solche Pflicht nach Stand der Technik.
Aktuelle Themen, wie Digitaler Kill Switch, Remotely Deactivation, Cloud und Digitale Souveränität, bezeugen die zunehmend bedrohliche Macht der Tech-Unternehmen und grossen Software-Hersteller. Da die Zusammenarbeit mit deren Support-Zentren weltweit zur täglichen Routine aller IT-Betriebe gehört, stärkt der Upload nicht-anonymisierter IT- und KI-Diagnose-Daten diese Machtfülle zusätzlich - und das massiv.
Der Autor

Quelle: Stephen Fedtke
Stephen Fedtke ist Wirtschaftsingenieur und Head of Technology von ENTERPRISE-IT-SECURITY.COM, ein auf IT-Sicherheit und Compliance-Lösungen spezialisierter Dienstleistungsbereich des Unternehmens Dr. Stephen Fedtke System Software. Außerdem ist er Autor und Herausgeber im Verlag Springer Vieweg.